先进芯片不等于先进算力,腾讯讲解云上训练大模型必要性
如火如荼的国内大模型创业潮中,高端芯片的短缺引发的算力压力一直是行业担忧的关键点。4月14日,腾讯宣布两大事宜——首发英伟达H800,以及发布高性能计算集群,缓解大模型趋势下的算力压力。
所谓“高性能计算集群”,主要采用腾讯云星星海自研服务器,搭载英伟达最新代次H800 GPU,服务器之间采用3.2T超高互联带宽,为大模型训练、自动驾驶、科学计算等提供高性能、高带宽和低延迟的集群算力。
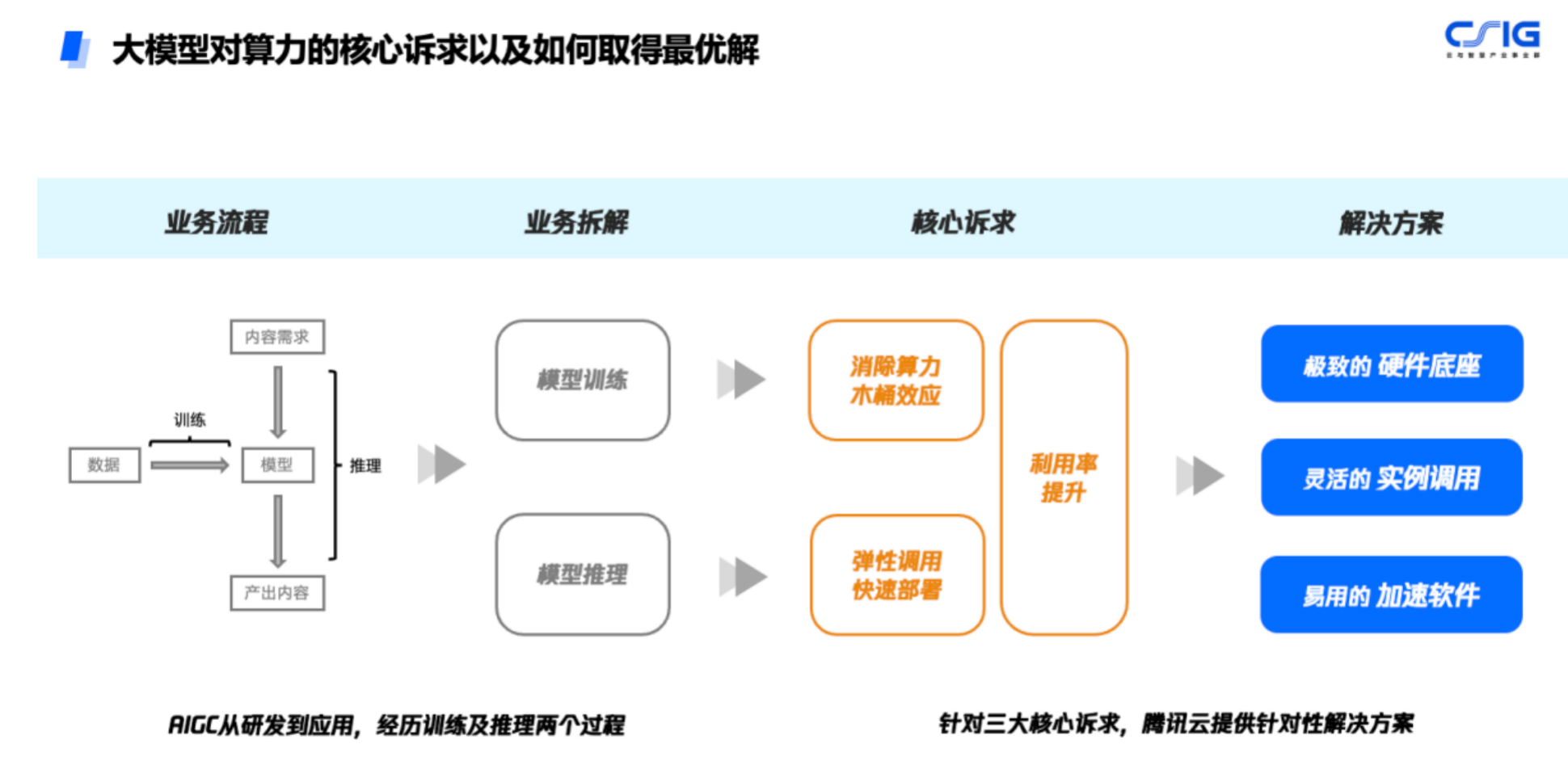
大模型带动算力需求激增
算力问题之所以成为行业头疼的难题,是因为当前大模型进入万亿参数时代,单体服务器算力有限,需要将大量服务器通过高性能网络相连,打造大规模算力集群。
此前接受采访时,腾讯云异构计算产品总监宋丹丹对第一财经记者表示,大模型是目前需求比较旺盛的业务,行业对算力的要求分为训练和推理两个阶段。训练需要短时间内并行算力非常全,算力非常大,且要在短时间内能够做到交付,所以对于算力的量级、稳定性、性能,以及弹性扩缩容的能力有比较高的要求。进入推理阶段,大模型对于单位算力的性价比、成本以及算力所处的位置与端应用的服务是否能够快速连接的要求较高。
目前来看,宋丹丹认为大模型所处的阶段还处于训练需求的爆发期,行业需要的还是一个海量的可扩缩容的高性能算力,并且这些算力能够稳定交付、稳定计算。因为中间打断一下,整个训练过程就会暂停,所以对于算力的稳定性要求很高。
对于目前行业对算力需求的变化,宋丹丹表示,一些新入场的业务确实有了新的增量,如之前的异构计算面向的领域主要是三大方向:一个是科学计算,如天气、地理测绘、医药研发;其次是渲染视觉类的,比如XR、VR的视觉服务、渲染,包括影视渲染、动画渲染、二维3D渲染等;第三类就是AI的SaaS和PaaS的应用服务。
现在的算力增量在腾讯云看来,可以笼统地可以划归到之前的AI传统服务里,只不过它的需求从原来的推理向和渲染更多地走向了训练向,更多的客户开始自己训练AI模型,这是目前市场的变化。

先进芯片不完全等于先进算力
算力需求暴增的当下,行业普遍将芯片,尤其高端芯片的短缺视为重要限制,但在腾讯云看来,当前大热的人工智能大模型需要海量数据和强大的算力来支撑训练和推理过程,其中数据主要由服务器和光模块存储、运输,算力支撑则依赖各类芯片。
但用上了先进芯片并不代表就拥有了先进算力,原因在于高性能计算存在“木桶效应”,一旦计算、存储、网络任一环节出现瓶颈,就会导致运算速度严重下降。
比如目前GPU并行是大模型训练的必备技术,不同于传统并行以加快计算速度为目的,大模型的并行计算往往还要考虑怎样将庞大的参数有机地分布到多张GPU卡中,并保持不同GPU卡之间有效的通信,整体配合完成大模型的训练部署。
即使是目前业界已有的GPU分布式训练方案,也严重依赖于服务器之间的通信、拓扑、模型并行、流水并行等底层问题的解决情况。如果只有分布式训练框架,甚至都无法正常启动训练过程。这也是为什么当时 GPT-3 已经发布一年,却只有少数企业可以复现 GPT-3。
因此,先进算力的背后是先进芯片、先进网络、先进存储等一系列的支撑,缺一不可。此次腾讯自研的星脉网络,为新一代集群带来3.2T的超高通信带宽。腾讯方面的实测结果显示,搭载同样的GPU卡,3.2T星脉网络相较前代网络,能让集群整体算力提升20%,使得超大算力集群仍然能保持优质的通信开销比和吞吐性能。并提供单集群高达十万卡级别的组网规模,支持更大规模的大模型训练及推理。
另外,腾讯云自研的文件存储、对象存储架构,具备TB级吞吐能力和千万级IOPS,充分满足大模型训练的大数据量存储要求。
芯片方面,此前,腾讯多款自研芯片已经量产。其中,用于AI推理的紫霄芯片、用于视频转码的沧海芯片已在腾讯内部交付使用。至于此次首发的英伟达H800芯片储备数量问题,截至发稿,腾讯方面暂未回应。
独家 | 李斌内部讲话回应换电业务可持续性:首个合作换电的车企将落地
李斌回应称,换电是蔚来巨大的先发优势,目前已经到了面向全行业开放的时刻,明天就会发布第一家合作,后面还有4~5家在谈。锤子财富2023-11-20 19:50:050000独家调查|瑞幸、库迪贴身肉搏掀咖啡大战,星巴克该怎么“卷”?
咖啡市场已经硝烟四起,在资本和新一轮咖啡品牌加盟热的助推下,加速开店、新品竞争、跨界营销等都成为各大商家互“卷”的方式。咖啡赛道如今如火如荼,甚至有白领辞职后投资数十万元进入咖啡赛道开店。那么咖啡店究竟好不好做?有没有投资前景?如今的咖啡市场竞争格局又是怎样的呢?锤子财富2023-07-10 14:07:320000福州五城区:取消住房限购 购买商品住房不再审核购房人资格
在本市鼓楼区、台江区、仓山区、晋安区、马尾区范围内购买商品住房(含二手住房),不再审核购房人资格。记者从福州市住房保障和房产管理局获悉,9月11日起,福州市调整房地产政策,五城区取消限购政策,不再审核购房人资格。一、优化购房服务流程。在本市鼓楼区、台江区、仓山区、晋安区、马尾区范围内购买商品住房(含二手住房),不再审核购房人资格。0000蚂蚁集团启动2024春招,聚焦AI;波音安全问题吹哨人突然死亡;宜家今年拟在全球所有市场进一步降价丨大公司动态
第一财经每日精选最热门大公司动态,点击「听新闻」,一键收听。【科技圈】苹果增加在华研发投资,首次宣布新设应用研究实验室已投入超10亿元0000融资保证金比例下调正式实施 证券板块午后拉升
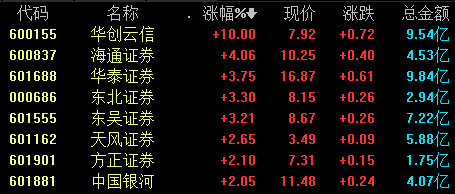
截至发稿,华创云信涨停,海通证券、华泰证券、东北证券、天风证券等跟涨。9月11日,证券板块午后拉升,截至发稿,华创云信涨停,海通证券、华泰证券、东北证券、天风证券等跟涨。锤子财富2023-09-11 13:39:200000