科大讯飞刘庆峰:中国大模型距离GPT-4的最好水平还有差距
1月30日下午,科大讯飞正式发布升级版星火V3.5大型语言模型以及首个开源大模型。据悉,星火开源大模型是在去年5月发布的星火1.0版本(130亿参数)大模型改进而来,增加了数据、能力、针对应用场景的工具链,并且针对国产安全可控进行了更系统性的设计,深度适配国产算力。
根据科大讯飞官方公布的测试结果,星火开源大模型在典型应用场景方面效果领先其他同尺寸开源模型超20%。

截至当天下午收盘,科大讯飞股价上涨近2%。1月29日,科大讯飞发布业绩预告显示,2023年公司净利预计同比增长15%-30%,达到6.45亿至7.3亿元,预计2023年实现营业收入超过200亿元,较上年增长约7%。
与星火开源大模型同时发布的还有科大讯飞的升级版星火V3.5大模型。据悉,该模型基于科大讯飞与华为联合发布中国首个全国产支持万亿参数大模型训练的"飞星一号"平台完成训练,但具体参数尺寸尚未对外公布。
科大讯飞董事长刘庆峰称星火3.5版本大模型在逻辑推理、语言理解、文本生成、数学答题、代码、多模态各个能力方面均实现大幅提升,进一步逼近OpenAI公司GPT-4 Turbo的最新水平。
刘庆峰告诉第一财经记者:"通用大模型关键是看谁的性能好,而大模型开源是为了建立生态,因此从技术水平来看,一般开源大模型都会略低于通用大模型。"
科大讯飞的开源大模型并不是国内首个。
更早之前,浪潮信息发布了完全开源且可免费商用的源2.0基础大模型,包含1026亿、518亿、21亿不同参数规模,此外国内的开源大模型还有智源研究院的悟道·天鹰 34B大模型;上海人工智能实验室的书生·浦语大语言模型的升级版对话模型InternLM-Chat-7B大模型;清华大学团队的VisualGLM-6B、ChatGLM2-6B大模型;阿里巴巴达摩研究院的多模态大模型mPLUG-Owl;百川智能的Baichuan-7B、Baichuan-13B等。
展望2024年讯飞星火大模型发展,刘庆峰指出三点:首先,一定要在通用大模型的底层能力上持续对标国际最先进水平,从算法研究包括更小的算力上做出相对更优效果;其次是要真正让大模型"量质齐飞",不仅是行业应用,还要在很多关键技术创新上联动大模型;第三是大模型要建立在安全可控的平台之上,实现自主可控平台上的生态繁荣。
刘庆峰说道,一方面是要清醒理智看到我们与国外的差距,当前在小样本、快速训练、多模态深度学习训练、超复杂深度理解等领域,中国的大模型距离GPT-4的最好水平还有差距;另一方面 ,未来在对抗网络的深度连接等领域,需要整个创新的生态。
中国大模型的竞争正趋于白热化,近期又有新的一批国产大模型通过备案。上周,监管机构批准了第四批14个大型语言模型向公众开放使用,其中包括小米集团、第四范式和零一万物的AI大模型。据不完全统计,自去年8月以来,我国已经批准了总共超过40个大型语言模型。
汽车、家电等大宗消费补贴政策……上海国际消费中心城市建设再出实招
上海加速推进国际消费中心城市建设,把实施扩大内需战略同深化供给侧结构性改革有机结合起来,着力恢复和扩大消费,围绕提质,推进商文旅体展融合和数字赋能,构建大消费的新格局。0000《一闪一闪亮星星》成2023年预售票房冠军,曾因高退票率被疑票房“注水”
灯塔专业版显示,截至12月19日,淘票票上映首日场次的退票率14.3%,上映次日的退票率为10.5%,第三天退票率为9.3%,确实在业内属于较高的退票率。元旦档即将来临,最受欢迎的影片已在预售中崭露头角。12月19日,灯塔专业版数据显示,影片《一闪一闪亮星星》预售票房超2.68亿,是2023年的预售票房冠军,该片也打破了过去三年元旦影片预售票房。该片将于12月30日正式上映。锤子财富2023-12-19 23:41:400000百万年薪总裁失联,华昌达最新回复:已返回公司正常履职
已结束协助调查工作华昌达(300278.SZ)6月15日公告称,公司无法与公司副董事长、总裁陈泽取得联系,其处于失联状态。公司于6月20日晚间公告称,本周陈泽已结束协助调查工作,返回公司正常履职。经自查,公司目前各项工作均正常开展,生产经营活动有序推进。0000郑州全面实施优化生育政策:新生儿入户三孩家庭一次性补贴1.5万
《办法》明确,郑州市将投入“真金白银”,实施育儿补贴制度,着力降低生育成本。政策规定,对新生儿入户我市的一孩、二孩、三孩及以上家庭分别一次性发放2000元、5000元、15000元的育儿补贴。9月1日起,《郑州市优化生育政策促进人口长期均衡发展实施办法》全面启动实施。新政将婚嫁、生育、养育、教育一体考虑,综合施策,精准施策,有针对性地减轻群众生育、养育、教育负担,让更多家庭“想生、敢生、愿生”。0004贵州茅台拟参与设立茅台招华基金及茅台金石基金
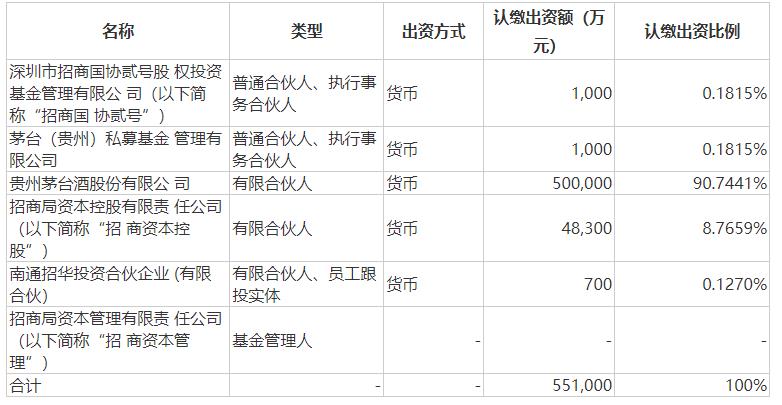
公告称,公司本次出资参与设立产业发展基金,主要目的是借助专业投资机构优势,提升资金收益率,为全体股东创造价值。5月18日,贵州茅台公告,公司拟以自有资金参与设立茅台招华基金,公司首期实缴20亿元;茅台招华基金认缴总规模为55.1亿元。拟以自有资金参与设立茅台金石基金,公司首期实缴20亿元;茅台金石基金认缴总规模为55.1亿元。据公告,茅台招华基金的合伙人、认缴出资及管理人情况如下:锤子财富2023-05-18 22:42:360000