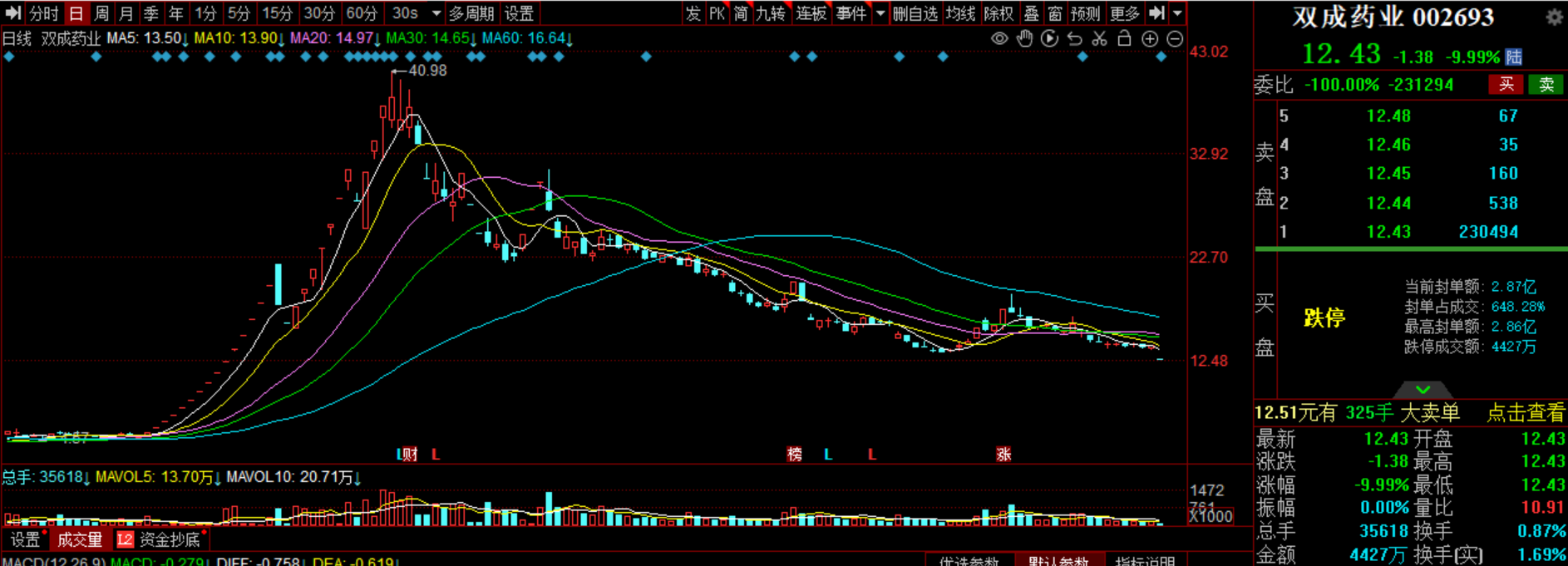
代表委员议AI:如何应对人工智能领域竞争?
全球掀起人工智能竞赛,全国两会期间,如何构建更好的AI生态、在竞赛中跑得更快,成为科技界人士讨论焦点。据第一财经记者梳理,来自科技界的政协委员和人大代表针对AI领域,颇为关注如何构建自主可控算力生态,以及如何加大投入、缩小与先进水平的差距。
其中,全国人大代表、科大讯飞董事长刘庆峰建议加快形成围绕国产大模型的自主可控产业生态,全国政协委员、知乎创始人兼CEO周源重点关注补齐优质中文语料数据短板等,全国人大代表,小米集团创始人、董事长兼CEO雷军建议在九年义务教育阶段设置人工智能通识课程。人大代表和政协委员关注人工智能发展的同时,近期人工智能教育已在校园逐步推进,“人工智能 ”也写入了政府工作报告。
算力生态自主可控
大模型背靠算法和硬件生态,自ChatGPT掀起大模型竞赛以来,GPU芯片需求大增,谁拥有更大的算力,谁就更有可能跑出更好的模型。以芯片为例,其背靠分散各地的全球供应链,竞争加剧背景下,拥有可用的国内供应链方案将是算力的一大保障。两会期间,多名人大代表和政协委员关注算力、数据等大模型产业生态自主可控。
全国政协委员、京东集团技术委员会主席曹鹏表示,ChatGPT发布以来,国内一大批科技公司争相发布大模型产品。算力是训练大模型的基础,寻求大模型算力集成设施国产化替代迫在眉睫。只有拥有自主可控的算力底座,国产大模型才能够在这场AI竞赛中取得先机。他建议抓住大模型发展契机,通过政策鼓励国产化GPU适配国产的算力调度软件,建设自主可控的智算基础。

算力方面,全国政协委员、中国科学院计算技术研究所研究员张云泉则指出,国内能用于大模型训练的国产智能算力芯片创新和供应显著落后。解决算力瓶颈可以从加大国产高端AI芯片研发、集中AI芯片研制力量、设置智能算力发展专项组着手。
关注自主AI生态建设的还包括刘庆峰,他建议在2017年《新一代人工智能发展规划》基础上,瞄准我国通用人工智能发展中需重点补上的短板进行设计,系统性制定国家“通用人工智能发展规划”,由国家高位推动规划制定和落地,在行业应用和价值创造上打造我国的比较优势。他还建议,以专项的形式从算力、数据、算法上在未来5年持续支持我国通用大模型的研发攻关,加快形成围绕国产大模型的自主可控产业生态。
“支持国产大模型向开发者开放,开展大模型测评体系和开源社区建设,降低研发和使用成本。建议推动国家级高质量训练数据开放和共享。建议加快脑科学与类脑智能、量子计算等领域与人工智能关键研究的协同攻关,形成交叉学科的突破,并加速通用人工智能技术相关的法律法规制定与审议。” 刘庆峰表示。
资金流入是促成AI生态完善的推手。近期业界对AI芯片的关注度增加,在海外,有消息称OpenAI首席执行官萨姆·奥尔特曼已在争取投资,以建立AI芯片企业,日本软银集团创始人兼首席执行官孙正义则准备为AI芯片企业筹资最多1000亿美元资金。一名国内AI芯片企业负责人告诉第一财经记者,大模型兴起后投资界对AI芯片的关注度已经增加,近期公司拿到一笔融资,但相比海外,国内投资人对一些新架构AI芯片的认知度相对有限,希望后续投资界的支持能加快行业发展,研发合作生态也能得到完善。
如何面对差距
“在互联网应用、人工智能领域,中国可以说是唯一能和美国形成竞争的。美国有很大优势,但中国在这个领域可以说超过其他发达国家,互联网技术应用、人工智能技术应用以及生成式AI方面处在日本、欧洲传统发达国家前面。”接受第一财经等媒体采访时,全国人大代表、TCL 创始人、董事长李东生表示,中国创新能力提高是驱动高质量发展的重要因素。
如何赶超人工智能先进水平,具体而言,国内大模型企业如何缩短与OpenAI的距离,成为两会期间的焦点话题,多名政协委员、人大代表针对促进国内AI产业发展提出建议。
全国政协委员、360集团创始人周鸿祎表示,中美在人工智能领域的竞争,一方面是对抗OpenAI的通用大模型基础战,另一方面是差异化、特色化的大模型应用战。当前,中国在通用大模型核心技术上赶超美国还需时间,但在大模型应用方面,2024年是大模型应用场景元年,国内可以走出一条具有中国特色的大模型发展之路。
针对推动大模型垂直化、产业化落地,周鸿祎建议政府、央国企率先提供更多应用场景,为发展垂直化、小型化、低成本的大模型开放更多“小切口、大纵深”落地机会。他还表示,大模型与业务场景的融合是实现智能化转型的关键,国家应鼓励企业拿出一至两个业务场景与大模型融合,创造可落地推广的与业务紧密融合的大模型。
周源则指出中文语料数据短板。他表示,ChatGPT训练数据中中文资料比重不足千分之一,而英文资料占比超92.6%,国内许多从事大模型开发的研究机构和企业进行模型训练时,不得不依赖外文标注数据集、开源数据集,或爬取网络数据,这限制了我国人工智能技术发展和创新应用推进。一些获取数据的方式面临法律风险,数据还面临耗尽的风险,据Epoch AI 人工智能预测组织的研究报告显示,AI公司可能在2026年前耗尽高质量文本训练数据。
周源建议建立数据合规的监管机制和评估办法,加强数据安全和知识产权的保护措施,并加快高质量中文数据集的开发与利用,探索数据要素交易模式,加大政府主导的公共数据资源开放共享。
此外,雷军建议将人工智能纳入教育培养体系,在九年义务教育阶段设置人工智能通识课程,并大力推进高校人工智能相关专业的建设。“从长期趋势看,各行各业对掌握人工智能基本技能的人力需求正急剧增长,而我国在顶尖人工智能人才储备方面还存在明显不足。”雷军表示。
张云泉则表示,目前人工智能相关人才培养上存在教育资源分配不均、课程内容更新滞后等问题,建议设立“生成式人工智能教学资源共享平台”,以鼓励学校间根据生成式人工智能的技术特点,共享教学内容资源和教学计算资源。
值得注意的是,政协委员和人大代表关注人工智能教育的同时,国内人工智能教育近期已有推进动作。近日,教育部办公厅公布中小学人工智能教育基地名单,确定184个中小学人工智能教育基地。多所高校也披露了涉及人工智能领域的课程或规划,其中南京大学宣布今年9月面向全体本科新生开设人工智能通识核心课程,清华大学将建设100门人工智能赋能教学试点课程,清华大学校长李路明在相关会上表示,学习未来将在资源、规划、标准等方面持续发力,促进人工智能深度融入教育教学等工作。
2023暑期档总票房超206亿元 创中国影史多项纪录
包括:创中国影史暑期档票房新高、创中国影史暑期档观影人次新高、创中国影史暑期档场次新高、创中国影史暑期档连续破亿新高、创中国影史大盘连续破亿新高、4部影片超20亿创暑期档新高。初步统计数据显示,截至8月31日24时,2023年暑期档电影总票房达206.17亿元,总观影人次5.04亿,总场次3460.7万。0000京东物流001号员工退休;“人为什么一定要周六休息?” 三七互娱回应创始人言论;周鸿祎回应网红程前道歉丨大公司动态
第一财经每日精选最热门大公司动态,点击「听新闻」,一键收听。【科技圈】荣耀首发意识识别人机交互操作系统MagicOS8.0日前,荣耀发布了自研操作系统MagicOS8.0,它突破了传统基于需求查找服务的方式,支持手势、眼动、自然语言、语音、图片等多模态的交互方式,可智能识别用户意图,进行推理决策,主动提供个人化服务,首次实现了意识识别人机交互。(证券时报)0000申万宏源两高管履新,黄昊任集团副董事长、张剑任证券公司总经理
张剑升任申万宏源集团和申万宏源证券党委副书记,以及申万宏源证券副董事长、总经理。申万宏源高层变动,黄昊当选为申万宏源集团副董事长。另据第一财经记者获悉,张剑升任申万宏源集团和申万宏源证券党委副书记,以及申万宏源证券副董事长、总经理。2月29日晚间,申万宏源发布公告称,选举黄昊为申万宏源集团第五届董事会副董事长。任期自2024年2月29日至第五届董事会届满。0000印度番茄价格狂飙近6倍,真人版“偷菜”在各地上演
番茄和洋葱在印度不仅是蔬菜,还有政治属性。“如今番茄已经卖到了一公斤200印度卢比(约合人民币17.4元),真是个天文数字。”住在印度经济中心孟买的居民桑贾伊告诉第一财经记者。锤子财富2023-07-27 22:56:510000