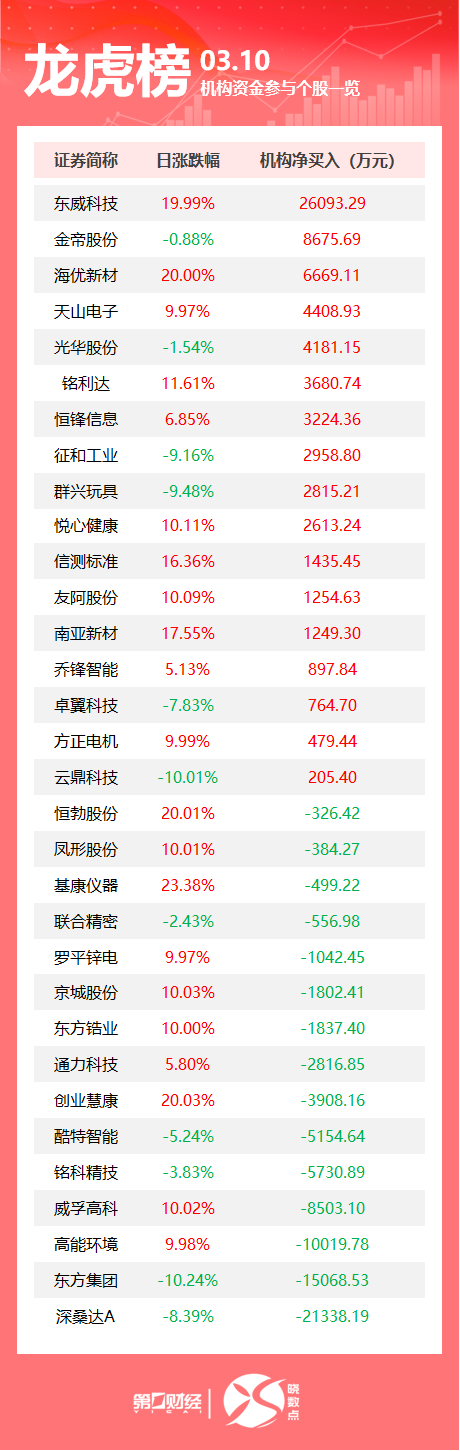
李彦宏给开源大模型泼冷水,他们却有不同看法|解码AI
大模型究竟开源好还是闭源好?近日,围绕开闭源的路线之争,因百度董事长李彦宏的一则内部讲话再掀风浪。
4月11日晚,百度董事长李彦宏的内部讲话曝光,给开源大模型泼了不少冷水,他称大模型开源的意义不大,闭源模型在能力上会持续领先而做模型的创业公司既做模型又做应用的“双轮驱动”不是一个好的模式。
“1.关于开闭源之争,核心是要看谁在开源。2.双轮驱动,是一线创业AGI公司的唯一解。”第一财经记者独家获悉,当晚,百川智能CEO王小川在一次微信群讨论中发表了不同观点。
在群里,金沙江创投主管合伙人朱啸虎也表示:“GPT4就能实现90%以上的商业需求,开闭源无所谓了,以后大模型API就是自来水的价格。”他又补充道:“但是用户需要的是纯净水,气泡水,乌龙茶……”
大模型生态社区OpenCSG的创始人陈冉在接受第一财经记者采访时表示,自己对于开源意义不大的说法“严重不认同”,无论是国内还是海外,大模型开源都已经成为一大趋势,且开源趋势会促进和推动行业在这之上的商业化,快速迭代、快速试错、共创共担,“开源只会越来越澎湃向上”。
在业界,坚定认为闭源大模型好于开源大模型的业界人士,与推动大模型开源者形成两股分流。第一财经记者与多名业内人士交流了解到,闭源和开源大模型在应用场景上形成了初步分化,两者各有利弊,但在大模型应用初期都有生存空间。
闭源还是开源好?
在国内科技大厂中,百度、字节、腾讯、华为等公司目前尚未公布过开源大模型。与此同时,也有不少企业选择了闭源与开源并行的路线。截至目前,包括阿里通义千问、百川智能、360、昆仑万维、智谱AI、浪潮、智源、科大讯飞、零一万物、APUS等都曾发布不同参数的开源大模型。其中达到千亿参数的开源大模型有APUS-xDAN 大模型4.0(MoE)(1360亿)和浪潮信息的“源2.0” 102B(1026亿)。
为什么李彦宏认为大模型开源的意义不是很大?在内部讲话中,他给出的理由是,有商业模式的闭源模型才能聚集人力和财力,中国和美国最强的基础模型都是闭源的,而最好的小模型都是大模型降维做出来的,而且闭源在成本、效率上有优势,同等能力闭源模型推理成本更低,响应速度更快。
他还有另一个理由,即模型开源跟传统软件开源如Linux、安卓不同,“虽然开源模型Llama也鼓励大家贡献各种各样的数据、代码,但实际上最主要的开发者就是Meta,不是一个真正大家一起来协同开发的产品。”
站在“闭源”一面的,还有月之暗面创始人杨植麟、他此前曾在接受采访时表示,闭源会有人才聚集和资本聚集,最后一定是闭源更好,海外有几百个基于开源扩散模型Stable Diffusion的应用,但没有一个跑出来。
杨植麟此前还曾提到,以前所有人都可以贡献到开源中,而现在大模型开源本身还是中心化的。截至目前,月之暗面并未公开提及有关开源大模型的具体计划或项目。
更早之前,人工智能科学家沈向洋在一个行业论坛上谈及大模型开源闭源路径之争。他认为,业内第一名一定是闭源,第二名他仍然踌躇不定,第三名才会是开源。
但总有人相信开源的力量。
一家开源不同参数规模的模型,同时也做闭源大模型的负责人告诉第一财经记者,模型的能力在不断发展,AI领域的技术创新和突破一直没有停止过。不同的企业和开发环境,会对模型尺寸、模型能力,以及背后的资源有不同的考虑。有的时候大家考虑的是极致的性能,有的是有充分的资源,需要更高质量的模型。
还有从业者对记者表示,李彦宏的意思是创业者依赖百度大模型就够了。但目前大模型还处在发展初期,远没有谁一家独大或者垄断行业。即便百度是国内较早入局大模型的一个,现在也正面临着月之暗面Kimi的突袭。
王小川也认为,开源和闭源并不像手机中iOS或者安卓操作系统只能二选一,开源确实容易“建立人品”,“朋友多多的”,让大家迅速了解和评测大模型的好坏。同时开源也是为商业化做准备,如果大家用起来觉得不错,当需要更好的服务和更大的参数时,可以探索进一步的商业化路径。
此前,阿里云CTO周靖人在接受包括第一财经等媒体采访时也曾回应路线之争,他称开源社区已经蓬勃发展起来了。他称,阿里云的初衷不是把模型攥在自己手上去商业化,而是帮助开发者,开源生态对促进中国大模型的技术进步与应用落地,以及生态的蓬勃发展至关重要 。
“从资源、数据和人力看,有商业模式的闭源大模型比开源大模型做得好的说法,一定程度上是成立的,原因是模型训练成本高,需要财力支持,例如训练一次要1000万美元。”新浪微博新技术研发负责人张俊林告诉记者。但从另外一个角度看,这个说法又不完全正确,因为现在很多开源大模型也是大公司做的,也有资源投入。
上海人工智能实验室领军科学家林达华教授此前接受第一财经采访时表示,闭源可能会在产品打磨上做得更强,所以产品成熟度各方面会更好,而对于开源模型来说,在产品成熟度上虽比不过闭源模型,但它能够支撑更广泛的从业者使用并进行二次开发,“最后可能开源模型的真实市场占比会非常高”。他认为,开源闭源会呈现出一个互补的道路,这与过去计算机技术发展潮流里操作系统领域的windows和Linux类似。
开放原子开源基金会资深法律顾问刘伟此前在GDC大会上表示,闭源模型有几个瓶颈,一个是云端推理的成本太高,如果并发需求很高可能随之产生很大的延迟。模型越大其灵活性和经济性越低,还有模型通常的幻觉问题可能也需要场景的支持才能进一步结合。
“开源模型胜在开源小模型上,可以灵活部署到终端设备上,包括PC、手机上可以实现低迟延推理的AI体验,可以用高质量的数据训练出垂直领域的应用,可以加快大模型在应用中赋能千行百业中,也就是说闭源的‘病’开源刚好都可以‘治’。” 刘伟提到。
MiniMax 技术副总裁安德森此前对第一财经记者表示,开源和闭源各自都有存在的优势和价值。开源能吸引更多开发者共同参与,加速技术的发展和普及,也能激发出更多的创新和创意。闭源模型的质量和稳定性更可控,能更好地保护知识产权、推动商业化落地。“我认为开源和闭源可以相互补充,形成一种更加开放、协作和创新的发展模式,共同推动大模型领域的发展。”
大模型开发者高晓安(化名)去年便开始根据开源模型微调并在开源平台上发布项目,他认为,开源给大模型生态带来了有利的改变。“大模型开发者可以基于开源模型做许多二创工作,出现了各种版本的StableDiffusion模型,各种基于Llama模型的中文Llama模型等,这是闭源模型无法做到的。”
高晓安还认为,开源大模型的另一个优势不能忽视,相比使用将公司资料‘喂’给闭源模型可能造成的数据泄露问题,收集独有的业务数据以训练开源模型则少了这方面忧虑,经过训练的模型亦可媲美甚至超越ChatGPT等闭源模型。当然,开源大模型还有一个优点,即给大模型企业“打广告”,包括谷歌、阿里、百川智能在内,都开源了参数量较小的模型,参数量较大的模型则闭源甚至收费。
开源ToB闭源ToC?
谈论开源大模型好还是闭源大模型更好,一个潜在语义是两者会在相同的应用场景互相较量。但实际上,目前开源大模型和闭源大模型已形成了一定程度的分化。有大模型开发者告诉记者,基于免费和数据安全考虑,很多公司已在开源大模型的基础上做出了自己的大模型。
“开源和闭源形成两个阵营,场景上看,开源更倾向于To B,闭源更倾向于To C,是两个赛道。”张俊林表示,开源无法To C,因为不提供具体产品,不可能响应个人用户,但开源可以面向企业,企业可以基于开源大模型,获得在数据隐私性上的优势。
王小川认为,从To B角度,开源闭源其实都需要。未来80%的企业会用到开源的大模型,因为闭源没有办法对产品做更好的适配,或者成本特别高,闭源可以给剩下的 20%提供服务。二者不是竞争关系,而是在不同产品中互补的关系。
林达华提到,从ToB的角度来说,开源会比闭源更好,因为它有更大的开放性去做二次开发。虽然未来闭源模型厂商会推出平台化的服务,开发者在上面用其标准化的工具可以做单一行业和垂直方向的模型。但是各行各业的需求非常复杂和多样化,可能并不是标准化的一套工具链能全部覆盖的。
“很多行业的企业和机构会有需求,想自己掌控整个模型的迭代,引导到自己需要的方向上去,但他们没有基础模型的投入,也不愿投入太大或没有这个能力,在这种情况下开源模型对他们来说是个最好的选择,可以围绕它做各种细节上的二次开发,这种开发不一定是标准的工具链能够支撑的。“林达华表示,未来这种开源的模式能够支撑经济体系里大量的产业需求。
对于闭源模型来说,更大的机遇在一些非常聚集的赛道,“如最后有可能会出现一个聊天APP,有非常大的C端流量,这一方向有可能就是一些大厂在一个商业化的体系里走出来。”
林达华认为,闭源大模型核心的逻辑在于它能够构成商业闭环,能够有大量的用户反馈,在固定的渠道里形成壁垒,假设最终其能找到真正击中用户痛点的地方,且通过用户的反馈能够去提升能力,那它就能占住一个赛道,在这里面进行商业化变现。最终,面向不同的需求,会有不同的模式,闭源和开源会形成一个互补的效应。
从大模型厂商的选择层面看,张俊林认为,选择开源是一种差异化策略。闭源大模型商业模式更加清晰,但弊端在于,如果模型效果做不到最好就很难收费。而如果走开源路线,虽然原则上模型不收费,但也可以据此形成商业模式,就像开源的Linux也有商业模式。所以厂商如果没有信心将大模型做到最好,开源便是一个选择。
张俊林认为,开源不一定就会成功,开源大模型即便不是最好,也应该有特点,开源大模型应有准确定位。例如走“小而强”路线,参数量小虽然不如参数量大的模型效果好,但有成本低、部署简单、对硬件要求不高的特点,可以部署至移动设备,应用场景多。另外一种选择则是做大参数,例如Grok,主打性能好的特点。
高晓安在体验后对记者表示,开源大模型和闭源大模型的做法也存在差异。虽然近期开源的Grok-1参数量达到上千亿,但很多开源大模型参数量只有70亿、130亿参数,如阿里云Qwen-7B、Baichuan2-13B。他告诉记者,相比闭源大模型比拼参数,这些小参数量开源大模型能通过堆更多预训练数据,达到较好的效果。
“同样的数据量情况下,更大参数模型的训练收敛速度更快,效果也更好,但训练成本也高很多。而小一些的模型部署成本更低,在实际业务中使用更友好,且有一些实验表明,70亿和130亿模型预训练数量还没达到饱和的程度。”高晓安认为。
张俊林也认为,现在小模型的能力已在快速提升,且能力还看不到上限,原则上只要给小模型更多数据,效果还会持续上升。
不过,高晓安认为开源大模型也有明显弊端,若不谈开源大模型的广告效应,开源大模型本身商业化仍存在一定难题。开源模型可以考虑针对商用版本收费,但在开源大模型竞争激烈的情况下这种做法比较困难。
开源公司的盈利点在哪里?林达华认为,开源厂商可以建立一种服务,“有价值的不完全只是模型本身,而是连带着它的服务,因为基于开源模式做二次开发是相当复杂的事情,在没有足够的技术支持的情况下,做这个事的成本会非常高,这时候技术服务的价值就能够发挥出来。”
对于开源的商业模式,陈冉认为,这个打法就像互联网时代移动应用的市场模式,“免费试用一段时间,后面有企业包装后的功能或者服务,这个东西也相当于汽车里的发动机,直接用不起来,需要包装成整车(企业功能)。”
“大模型会展开一个非常大的商业空间,不同的方式不同的点上,会有很不一样的模式,最忌讳的是把所有东西套到一个‘鞋子’上面。”林达华对第一财经说。
金融服务碳中和大有可为 交通银行助力打造国际绿色金融枢纽“朋友圈”
当前,全球可持续发展正步入关键节点,随着温室气体排放创历史新高,科学家不断对气候危机的紧迫性发出警告,产业转型亦成为全球备受瞩目的议题。对于中国而言,实现碳中和、碳达峰目标则是贯彻新发展理念、构建新发展格局,推动高质量发展的内在要求。0000凯文·凯利来沪称爱玩密室逃脱,鼓励年轻人主动定义工作
凯文·凯利的一个建议是,改变并尝试找到你想花更多时间做的工作,而不是试图减少你花在工作上的时间。9月12日晚,《连线》杂志创始主编凯文·凯利携两本新书《5000天后的世界》《宝贵的人生建议》做客上海图书馆东馆。读者热情高涨,排队签名的队伍从阅剧场一直延伸到大门口,也有读者拿着他最有名的著作《失控》《必然》来到现场。锤子财富2023-09-15 12:27:010000英飞拓董事长、大股东联手减持,所得资金将全部借给上市公司
本次减持所得的资金将全部借给上市公司,资金用途包括但不限于日常生产运营、项目交付、债务偿还等,利率参照同期银行贷款利率。锤子财富2023-06-29 21:40:330000七家汽车巨头联合进入美国充电桩蓝海,特斯拉还能保持一家独大吗?
尽管其他汽车厂商开始奋起直追,但特斯拉的提早布局已收获了回报。美欧日韩七家汽车公司正联合起来,试图对抗主导美国电动汽车市场的特斯拉。当地时间周三(26日),宝马、通用汽车、本田汽车、现代汽车、起亚、梅赛德斯-奔驰和玛莎拉蒂母公司Stellantis等七家主要汽车制造商表示,他们计划共同投资10亿美元以上,以集团的形式在美国城市以及高速公路地段建设约3万个充电桩。锤子财富2023-07-27 19:11:410000神龙汽车人事调整,新一届领导班子如何打响反攻战?
神龙汽车迎来重大人事调整,新提拔的高管均在东风系有多年的工作经验。神龙汽车迎来重大人事调整。4月9日,神龙汽车召开干部大会,宣布了神龙公司领导班子成员调整决定。0000