业绩远超巴菲特和达利欧,西蒙斯怎样做量化投资
1
先让我再一次引用恩格斯这段著名的“合力论”——
“……有无数互相交错的力量,有无数个力的平行四边形,而由此就产生出一个合力,即历史事变,这个结果又可以看作一个作为整体的、不自觉地和不自主地起着作用的力量的产物。因为任何一个人的愿望都会受到任何另一个人的妨碍,而最后出现的结果就是谁都没有希望过的事物……”
我在一篇文章里写过,战争与革命都是这种“谁都没有希望过的事物”。现在这篇涉及投资、数学、人工智能、机器学习,你会发现,它们也是。核心便是,影响人的选择以及事物变化的因素太多了,并且这些因素之间还不断地相互反馈循环作用,这使得你几乎不可能真正准确地预测其走向;所谓对的预测,绝大多数只是运气够好,剩下的,则是预测的模型在一段时间内因为抓住了最重要的几个变量而显得相对成功,但你的成功反过来已经改变了所有变量(包括那些你没有纳入模型的变量)及其作用方式和相互关系,因而时间再拉长一点,只要你陷在成功的模型里(人性决定了你很难不陷在里面),你一定会撞墙。

恩格斯的“合力论”虽然大体沿用了19世纪略显僵硬的形而上学语言,但20和21世纪最前沿的数学研究,比如非线性偏微分方程,比如高维拓扑流形,再比如它们当下的实际应用——机器深度学习,究其本质,无非是用更科学和严格的方式,重写了“合力论”——所谓“无数个力的平行四边形”,无非现代数学中向量和向量丛的二维简化版罢了。
而我常常觉得,人们之所以对“量化投资”之类炫目的新事物一开始就抱有深深的误解,其根本便在于对真正的现代数学,包括以现代数学语言重写的恩格斯“合力论”理解太肤浅。
以下是我在知乎上读到的一位“专业人士”(个人标签是“算法设计人工智能”),基于(对大数据和技术分析的)陈腐之见,对量化投资所作的非常典型的一种“误读”:
“基本原理,短线、高频交易,即所谓的‘见利就走’。所谓的‘见利’是基于预测模型的‘实时机器学习’模型,对某个操作对象的价格数据实时监测进行序列价格曲线拟合,得到预测曲线y=f(t)和误差概率P(t),其中t为预测未出现序列号,y为该序列号时的价格,计算机根据跟定的希望获利值(此时的买进价和预测卖出价的差值),程序化自动下单。因此,西蒙斯量化模型完全不考虑外部条件(x1,x2,x3……xn)对价格的影响,只关注价格变化,快速买进卖出做高频短线交易,虽然每单获利很小,但保证高频获利的前提下,赢得最大获利概率Max[P(t)]。”
这种误读的关键,正在于经验让他难以超越低维度的视野,将数据及其建模仅仅视作“曲线”以及曲线与数据之间的简单“拟合”。而事实上,我们知道,以詹姆斯·西蒙斯在微分几何领域的数学成就,以文艺复兴科技公司所聚集的那数百位顶级的数学家、物理学家、天文学家、生物学家对真正前沿的数学的理解,这里出现的模型起码应该是“曲面”,更大可能则是任意维度的拓扑流形。
2
文艺复兴的模型为什么如此神秘?为什么至今没有离开的人能真正“泄密”?除了用人合同中严格的保密条款(其实我觉得其中故弄玄虚的成分居多),更大的可能,在于它压根儿很难被泄密,敞开了让你抄,你也不会抄。正如文艺复兴的高管们所透露的,连他们自己都无法确切地知道公司为什么会赚钱,为什么会亏钱。用非线性偏微分方程处理数据 高维拓扑流形建模 机器深度学习,其中每一样都是高度流动、自组织演化的,并没有一个可以让你直接抄下来用的方程或图表。特别是机器深度学习,其基于海量历史数据的高维模型(想想弦论中的六维卡拉比-丘流形),随时随地都在不断自我修正、深化、变形和涌现中,你抄什么?抄一个切片有什么用?
量化的高维建模与常见的统计学建模的最大区别,我以为在于统计学更多考虑的不是作为原因的变量及其相互作用,而是最终结果的概率分布,因此统计学模型或许在理论上非常有力,却不见得有多少实践价值——你按照统计学分布去投资,很可能会踩坑,因为统计学分布是大量结果的综合效应,而你的每一次投资却是一个当下的、高度不确定的一次性事件;按统计学分布去做,总体上固然有较高的获利概率,但你很可能没有足够的资本,在统计学效应足够显著以前,你就输光了。
而高维流形建模并不是仅仅基于概率,而是基于对大量可能相关的变量的辨认、筛选与测试,与统计学模型的“事后特征”不同的是,它完全是即时反应型的,时刻在(自动)调整模型中变量的特性、数量与相互关系。在人力计算时代,这当然是非常困难以至不切实际的事情——绝大多数多变量的非线性偏微分方程,在数学上是极难甚至无法求解的,数学家们在这些领域的核心工作,早已从求解变成了估值,甚至不是对解本身估值,而只是对可能有多少个解进行边界估值。但是计算机尤其是深度学习,让数据的高维建模变得现实了。计算机的高速数据处理能力,使其能在无数变量中出入自如,对这些变量及其关系进行大量的筛选、评估和运算;而深度学习使得计算机能够在人的脑力完全没有能力处理的层面上,通过大量的比对、拟合、回测,来自动建模、运转和改进。
高维模型不是针对大数据绘制一目了然的统计学曲线(如我们在股市K线图之类“技术分析”中常见的),而是针对无穷的局部小数据构建无数极其复杂的、高度流动性的拓扑流形——事实上,早在19世纪中叶,一度担任过罗斯柴尔德家族掌门人私人秘书的法国会计师亨利·勒菲弗,就一语道出了其中的关键:“套利活动是普通代数的有趣应用,而投机活动则需求助于几何学,因为无法仅单独使用算术、代数或简单语言就能将这些交易组合理解清楚。”只不过今天数学家们对几何,特别是高维的拓扑几何和代数几何的理解,已经远远超越了勒菲弗那个时代的数学水平。
举个不那么准确但足够通俗的例子。比如石油价格的涨跌,在简化模型的时代,通常会出于思考和计算的效率考虑,被设定为几个主要因素的作用,比如欧佩克限售、美国探明的页岩储量又有增加、中亚的某条输油管因为民族冲突而被截断……你综合考虑这几个看上去很重要的变量,选择性忽视其他可能但不那么重要的变量,然后比对历史上类似情况下发生的价格波动,从而建立一个模型,去预测其价格走势。时下比较流行的因子投资,其所使用的多因子模型,其实就是这样通过一系列技术手段筛选出3~5个被认为是关键性的变量,围绕它们建模以测定资产的预期收益率。而在(真正的)机器主导的量化投资中,被考虑的变量可能暴增千百倍,那几个变量或许依然是最重要的,但是不那么重要的也不会被删除,只是占的权重稍低罢了。
更有甚者,我们还应该进一步利用计算机的强大算力和客观性,去发掘更多我们可能完全没有意识到在起作用的变量,因为我们对事物的认知必然被偏见与情绪等主观因素所极大局限,计算机的“非人性”正好可以用来“对冲”这一“人性的,太人性的”根本缺陷,从而大大扩展我们的视野。
而目前国内主流的量化投资机构,似乎主要还是靠策略开发人员个人去挖掘因子、调整模型参数,可以说从根本上偏离了量化投资的核心要旨——利用计算机捕捉人类因受限于眼界、注意力、反应速度等因素而无力捕捉的信息,从而抓住——几乎是无穷无尽但极其微小的——瞬时机会。真正的计算机量化模型必然不是一个或几个“策略”(虽然这好像是我们现在提起量化时的口头禅),而是人根本无从察觉更无法去主动建立的无数局部小模型的高度灵活的组合。这就是为什么在量化投资中,“程序化”远远要比“数量化”或“数据化”更根本,只不过这里的“程序”也不是普通的“程序猿”写得出来的——如果码农就能写,文艺复兴还招满坑满谷的顶级科学家干吗?
3
任一事件,都是无数变量作用与相互作用的结果,纳入尽可能多的变量来建立高维模型,利用现代数学在比如高维流形向量丛上的成果,来建立从前难以想象的复杂空间,以基于微分几何、几何分析等前沿数学的一系列技术工具,对其整体与局部的形态和度量加以把握,才能使数据的内在丰富性和相互关联性得到深度挖掘。
并且高维模型在判断当下局势的时候,并不是在简单地(也就是说粗糙地)拟合和比对历史与现实两条宏观曲线,而是在类似极小曲面这样最微观的层面上,对海量的历史数据中具有相似性的多变量作用模式进行筛选和匹配,做极为细致和即时性的具体对比。因此真正的高维模型恰恰不做预测,只做当下的高度机动性的即时应对——正如纳特·西尔弗所说:“我们要停止对事物进行预测的做法,并且承认我们的预言有问题。我们喜欢对事物做出预测,而我们的预言却总是出错。”量化投资之所以青睐高频极短线交易,除了通过放大交易量来提升总收益,另一个,我觉得也是更重要的原因恐怕就在这里——面对根本的不确定性,反应灵敏的即时应对比中长期预测要“科学”得多。
预测一般只对中长时段有效。比如所谓“分久必合,合久必分”,就是通过观察数个为期两三百年的长时段而作出的预测。而长度约为50~80年的康德拉季耶夫长周期,可以视为典型的中时段,其波动周期性也具有一定的预测功能。但是所有这些预测对短时段都无效,因为短时段上的事物处于类布朗运动中,尚未体现出统计学特征,即便你能计算出相关的概率,实际的指导意义也极为有限。
我们都知道比如一个中国古代王朝的生命周期大约是两三百年,所以在长时段上可以根据我们身处的时间点,大致预测今后繁荣或衰败的走向。但是开元初年的人显然不可能预测到安史之乱正在繁荣鼎盛的高潮中大踏步走来。人最容易犯的错误之一,是将预测的功能扩大化,试图将只对中长时段有效的预测手段强行运用于短时段以至当下。实际上,当下之事只能竭尽灵活之能事地加以具体应对,而不能基于自以为是的预测采取行动——这是绝大多数股民是韭菜的“科学原因”(当然,韭菜之为韭菜还有其“政治经济学原因”,在此不涉及)。
基于高维流形的人工智能——目前的机器深度学习是其很初级的形态——关键就是最大限度地缩减了固有模型的预测惯性,相反,模型本身在数据环境下每时每刻都在进行自反馈、自适应乃至自涌现。
当然,对于坚信符号主义路线的人,这一点是很难接受的,所以他们当然会攻击机器深度学习只是“黑箱”。然而真正的高维智能对人来说必然是无法理解的“黑箱”,因为它必然远远超越于人脑的数据处理能力,并进而远远超越于人的感知和思维能力。这个质疑实际上恰恰应该反过来,作为对高度发达的人工智能的判准,即所有未能呈现出“黑箱”特征的人工智能,根本算不上真正的人工智能。

《征服市场的人:西蒙斯传》
[美]格里高利·祖克曼 著
天津科学技术出版社·湛庐文化 2021年2月版
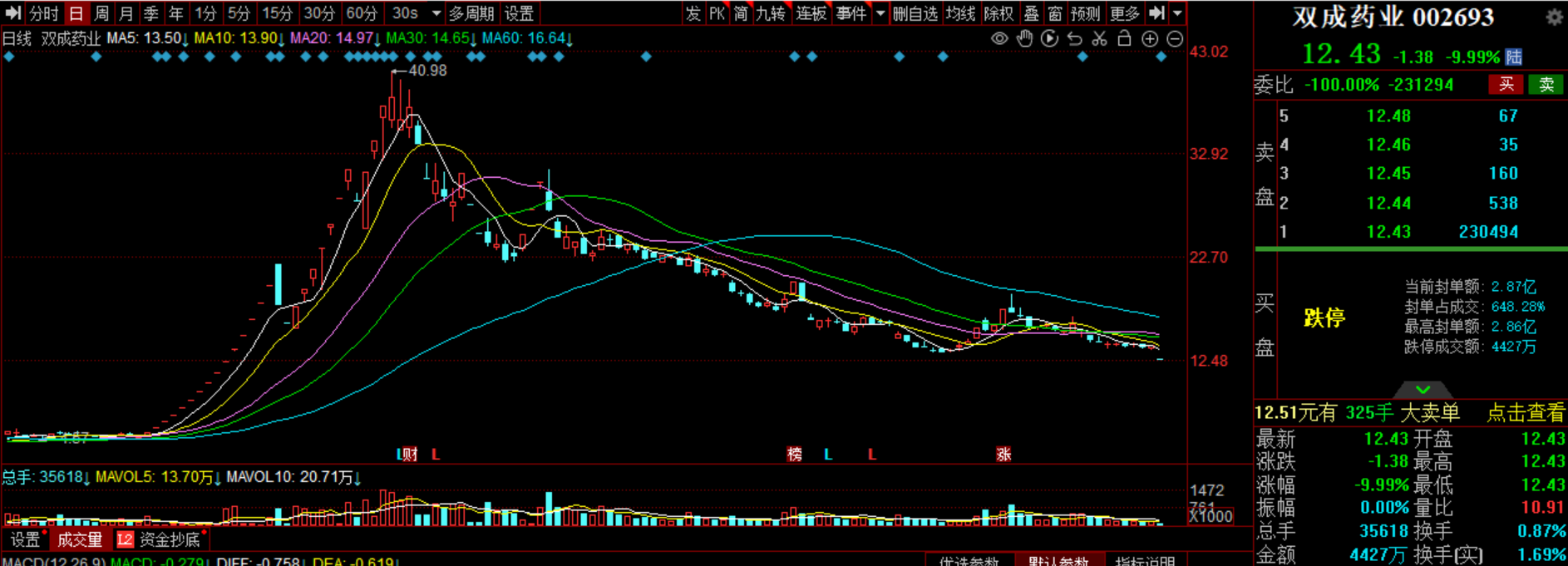
立讯精密:围绕消费电子主业并购整合,复制能力至新增长曲线
作为国内精密制造企业龙头,立讯精密(002475.SZ,下称“立讯”)起家于消费电子行业,并逐渐拓展至汽车、通信板块,如今已成为当之无愧的果链明星公司。2010年上市至今,立讯的营收和利润几乎实现了指数级上升:营收规模从2010年的10亿元增长至2023年的超2300亿元,归母净利润从1亿量级增长至百亿量级。锤子财富2024-12-26 18:50:100000中国东航:飞出“绿色飞行”新航迹 飞出帮扶“新航程”
从“绿色飞行”到产业帮扶,从可持续发展到全面乡村振兴,中国东航积极履行社会责任,并将可持续发展融入企业当下和未来的发展战略。飞出“绿色飞行”新航迹2022年减少碳排放超17万吨锤子财富2023-12-18 14:52:230000盘前必读丨证监会召开资本市场法治建设座谈会;MSCI调整今日生效
证监会党委书记、主席吴清主持召开资本市场法治建设座谈会,就完善资本市场基础制度、加强法治保障听取意见建议。【财经日历】2023年国民经济和社会发展统计公报公布;俄罗斯总统普京发表年度国情咨文;MSCI季度例行标的调整今日盘后生效;美国至2月24日当周初请失业金人数。美股周三延续调整,市场消化最新GDP数据和美联储官员评论,投资者关注即将公布的通胀数据对美联储何时开始降息的影响。锤子财富2024-02-29 10:41:280000露营产业三年走完十年路:进来很多、死掉很多、壮大很多
“大家都觉得这个市场进来就发财”,潮来了又退走了,同时也退走一批又一批入局者。从浙江金华市区出发,驱车一个小时,就能抵达全国旅游休闲用品的重要生产基地之一——武义县,金华政府官网2022年的数据显示,这里的户外用品产量和出口量占全国的40%以上。露营品牌黑鹿(BLACKDEER)和山扉(SunnyFeel)的工厂都落在这里。锤子财富2023-04-19 12:20:410000昔日P2P“教父”被判无期,非吸超千亿,旗下上市公司今年退市
金融草莽时代的终结。12月7日,广东省高级人民法院公众号发布消息称,深圳市中级人民法院对红岭创投电子商务股份有限公司(下称“红岭创投”)董事长周世平等人非法集资案一审公开宣判。被告人周世平犯集资诈骗罪、非法吸收公众存款罪,被判处无期徒刑,剥夺政治权利终身,并处没收个人全部财产。其余17名被告人犯集资诈骗罪、非法吸收公众存款罪、职务侵占罪,分别被判处有期徒刑十一年至二年六个月,并处罚金。0000