行业大模型如何保障用户数据安全?︱AI大模型十问(五)
“大模型行业从2023年10月开始进入到冷静期。为什么进入到冷静期?第一,大模型受关注不仅仅因为它的AI新技术,而要看场景在哪?也就是价值点在哪?第二,在实现价值的过程中如何保证数据安全?”用友iuap平台技术专家姚春雷在接受第一财经专访时表示。在行业大模型不断应用落地的当下,数据安全问题备受关注。
行业大模型,知识是核心。行业大模型数据来源除了一些公开数据外,还包括企业内部数据、大模型在交互过程中产生的数据,共同组成了大模型训练的语料基础。随着当前大模型应用爆发式增长,涉及到的数据量也随之大幅增加,数据安全的重要性越来越突出。
“当前数据安全问题主要体现在两个方面,一是数据泄露问题,二是数据权限控制问题。”浪潮通软平台软件与技术研究院总经理周祥国告诉第一财经。
目前,大模型数据泄露是用户数据安全中面临的主要挑战之一。“现在财务报销制度要想发布到公网,进行模型的二次训练是非常难的,因为没有谁敢把最基本的数据发出去,进入到模型训练层。”姚春雷举例称。
“目前业内保障数据安全的普遍做法是设置一个IaaS层,单独为用户做一个IaaS隔离,然后将数据放到IaaS层,IaaS层处理过以后还可以销毁。IaaS层做隔离一定程度上保障了数据安全,但没有办法把数据发布到公网,这个是比较大的问题。”姚春雷表示。
那么,面向企业的行业大模型如何保证数据安全?做私有化部署,即不上云端,计算和数据存储都在客户本地服务器进行。
“用友企业服务大模型YonGPT可以直接私有化到客户本地,客户的数据在不出网的情况下使用企业大模型的能力。客户的数据既能够在内网,模型也能有一个反馈结果,因此保证了客户的数据安全。”姚春雷称。
周祥国介绍称,浪潮海岳大模型支持用户本地私有化部署,支持自建垂域大模型。海岳大模型在提供良好的底座大模型以外,也为各行各业补上欠缺的“解题步骤”,比如行业数据再加工、行业数据的补齐等,用户通过自主录入企业知识作为大模型数据训练来源,基于模型“微调”对大模型进行自训练,助力企业拥有自己的行业大模型,保障数据安全。
不过,本地化部署又涉及到性价比的问题。本地化部署需要客户购买算力等基础设施,如果大模型需要的算力等基础设施成本过高,而大模型自身带来的价值并不匹配,那么行业大模型也难以商用。
“把大模型的参数量级降到一定程度,最大程度减少所需算力,而非动辄需要上百张或者上千张GPU卡。让企业客户享受大模型红利,这是用友一直在攻克的难题。”姚春雷表示。
与此同时,数据权限控制也是数据安全问题中需要重点关注的问题。要确保只有企业内部相关人员能够访问敏感数据,企业知识本地化是重要手段。
“浪潮海岳大模型以相关法律法规和道德准则为前提,在确保数据合法性和正当性的基础上,帮助企业构建企业专属知识库,对企业客户数据、财务数据、生产数据等企业专属知识进行梳理和统一管理,从而实现数据权限的有效把控。”周祥国表示。
在大模型应用时,也需要严格控制数据权限,防止未经授权的访问和潜在的数据泄露风险,保证模型输出的准确性和可靠性。此外,在行业大模型训练数据的采集、使用、存储、以及与第三方数据共享全流程中,也需要对数据进行数据加密、访问控制、安全审计、数据备份和恢复等措施来加强数据安全防护。
思谋科技的工业多模态大模型IndustryGPT也采取了类似的措施。“我们在各环节实施严格的访问控制机制,通过限制对数据的访问,以确保数据的机密性和完整性,有效防止数据的非法访问、篡改和泄露。”思谋科技联合创始人兼技术负责人刘枢告诉第一财经,通过建立完善的数据备份和恢复机制,可以在数据丢失或损坏时及时恢复数据,保证业务的连续性,同时降低数据泄露的风险。对于客户的核心数据,需要通过增强大模型能力,将客户数据始终留在客户侧,模型通过In-context Learning的能力直接提供服务。
“全面的数据清洗也是保证大模型安全的重要方式之一。”刘枢补充道,“在进行大模型训练之前,我们对所有数据和语料进行合规处理,包括数据清洗、数据标注、模型预训练等,可以有效降低模型输出内容的有害性和数据泄露风险。”
医药情报|百济神州达成ADC授权,百克生物净利预增超43%
百克生物业绩预增主要受益于带状疱疹减毒活疫苗的上市。重磅原创|中国大陆猴痘病例已达10例,为何突然增多?在过去的一周里,我国多地相继报告了猴痘确诊病例。截至目前,中国大陆已报告的猴痘感染病例数量已增至10例。值得关注的是,这些病例当中已经出现了本土传播,而不仅仅是境外输入病例。对此,专家呼吁保持冷静,称这种疾病不太可能导致大规模传播,因为猴痘病毒相对容易检测、控制和治疗。0000国家发改委:扩大内需特别是消费需求 持续扩大有效投资 稳住外资外贸的基本盘
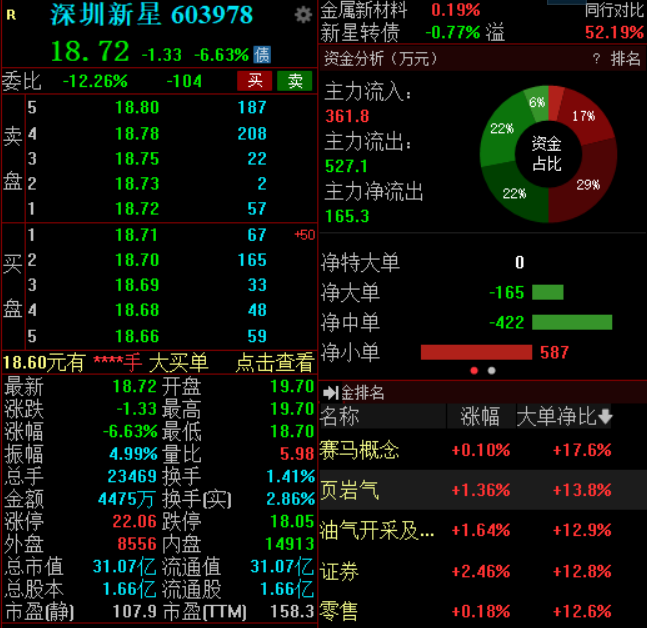
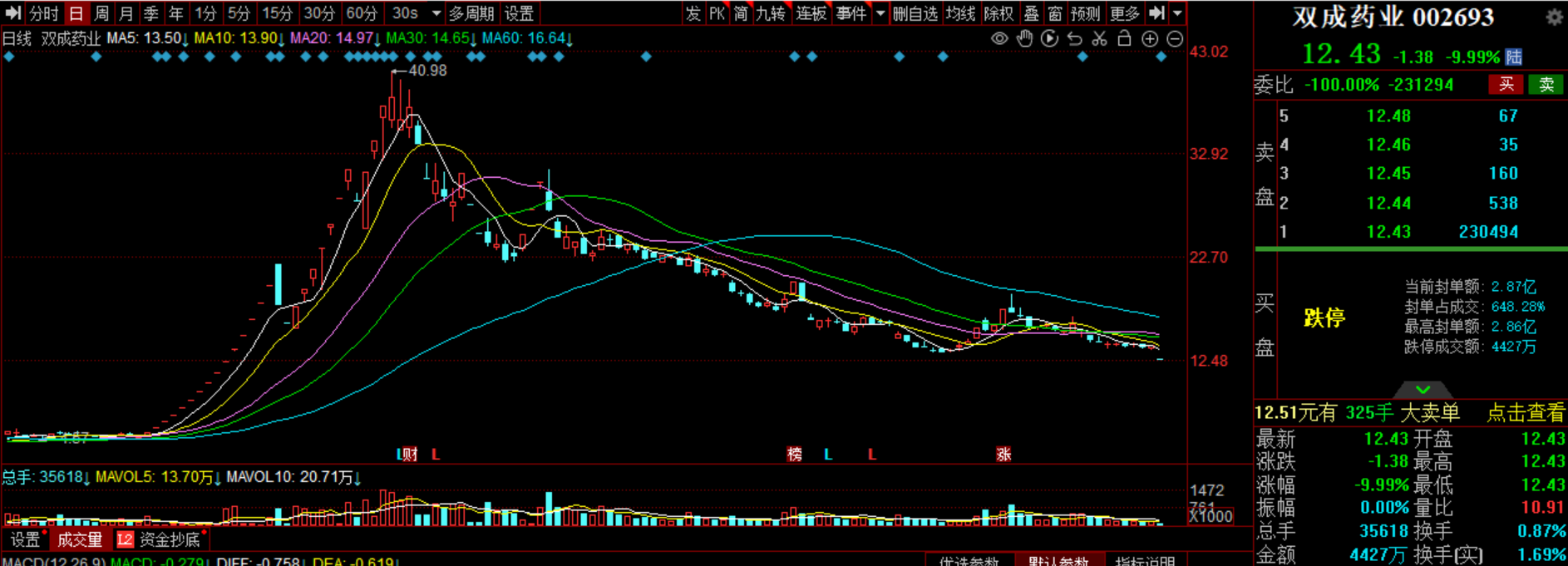
下一步,国家发展改革委将在解决制约民营经济发展的难点、堵点、痛点问题上持续发力。今年以来,中国经济的表现备受各界关注。前三季度,国内生产总值(GDP)同比增长5.2%,这表明中国经济总体恢复向好,这种回升向好的势头能否持续?中国经济的后劲又在哪里?带着这些问题,我们来到了国家发展改革委。记者:我们感觉今年经济增长实际上面临的挑战压力也不小。对目前的经济形势,您怎么看?00002022年净利最高预亏5200万元,深圳新星早盘大跌超6%
截至发稿,该股跌逾6%,报18.72元,成交额4475万元。4月17日,深圳新星低开低走,截至发稿,该股跌逾6%,报18.72元,成交额4475万元。深圳新星4月16日发布2022年年度业绩预亏公告,预计2022年度实现归属于母公司所有者的净利润为亏损4200万元至5200万元,与上年同期同比,将出现亏损。锤子财富2023-04-17 10:52:460000豫园灯会首次“出海”,复星还要携手支付宝打造元宇宙灯会
除了法国豫园灯会,复星旗下的豫园股份(600655.SH)也在推进旗下饮食、酒业、珠宝等老字号品牌“走出去”。法国当地时间12月15日晚,豫园灯会在巴黎正式对公众开放,这是复星打造多年的豫园灯会首次走出国门。作为上海豫园灯会的首个出海作品,法国豫园灯会将在巴黎展示上海的在地文化,包括豫园地标九曲桥和湖心亭,以及老上海人熟悉的“沪上八景”之“凤楼远眺”、“野渡蒹葭”、“海天旭日”、“龙华晚钟”。锤子财富2023-12-15 23:35:390000OpenAI遭指控:非法阻止员工披露AI安全风险
OpenAI尚未就此事作出回应。7月14日消息,OpenAI举报人向美国证券交易委员会(SEC)提交了一项投诉,指控OpenAI非法禁止员工就其AI技术可能对人类构成严重风险,向监管机构发出警告,呼吁对其展开调查。举报人在一封投诉信中称,OpenAI要求员工签署过于严格的就业、离职和保密协议,这些协议可能导致向联邦监管机构提出对OpenAI担忧的员工受到处罚。0000